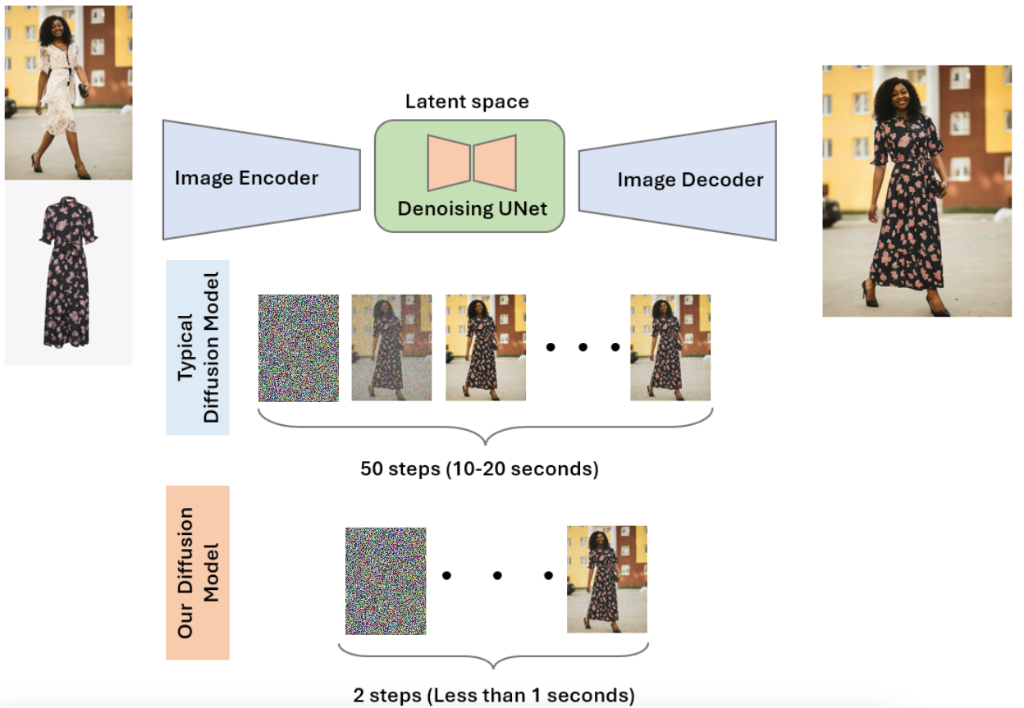
The Problem with Traditional Virtual Try-On
Diffusion models, the backbone of many state-of-the-art VTON solutions, excel at generating photorealistic images. However, their computational demands create significant barriers to real-world deployment. The core issue lies in their high inference latency—often requiring 50 or more steps to produce a single image, which translates to 10–20 seconds of wait time per try-on. This not only frustrates users but also drives up GPU usage, making costs unsustainable for large-scale applications.
Our Solution: Speed and Scalability
We reimagined the VTON pipeline to prioritize real-time performance, cost-efficiency, and uncompromised visual quality. Our approach focuses on streamlining the underlying technology to eliminate latency and reduce resource demands.
We achieved this through deep model architecture tweaking, multi-level deep training with different loss types, and finally applying quantization. These strategies significantly reduced computational overhead while maintaining output fidelity. Underpinning these advancements is our proprietary in-house dataset—a comprehensive, meticulously annotated collection of diverse images.
0.23s
Inference Latency
98%
Cost Reduction
4.35
Images / Second
Performance Benchmarks
On Nvidia L4 / RTX 4000A:
| Metric | Baseline (50 Steps) | Ours (2 Steps) |
|---|---|---|
| Latency | 10–20 sec | 0.23 sec |
| Cost/Inference | $0.01 | $0.00007 |
| Speedup | 1x | ~87x |
Transforming E-Commerce at Scale
For an e-commerce platform serving 50 million users monthly, traditional costs could reach $5 million. With our optimized 2-step model, that expense drops to just $35,000. Beyond savings, the near-instant experience keeps users engaged and drives higher conversion rates.